黑森林团队出的flux模型因其强大的参数,惊艳的细节效果广受欢迎,现在已经在各类AIGC平台占有很大的曝光量,甚至现在libulibu首页也是主推f1.0的lora模型,因其少量数据的微调就能获得很好的效果受到很多人的喜欢。
因为职业关系,我在工作上也尝试了flux-lora模型训练,接下来我分享pinokio-flux-gym训练工具和flux train-aitoolkit 两种工具的差别。
优点:安装简单,易上手
缺点:只能训练flux-lora模型,如果想要训练sd1.5和XL模型你需要在社区中找到Kohya训练工具
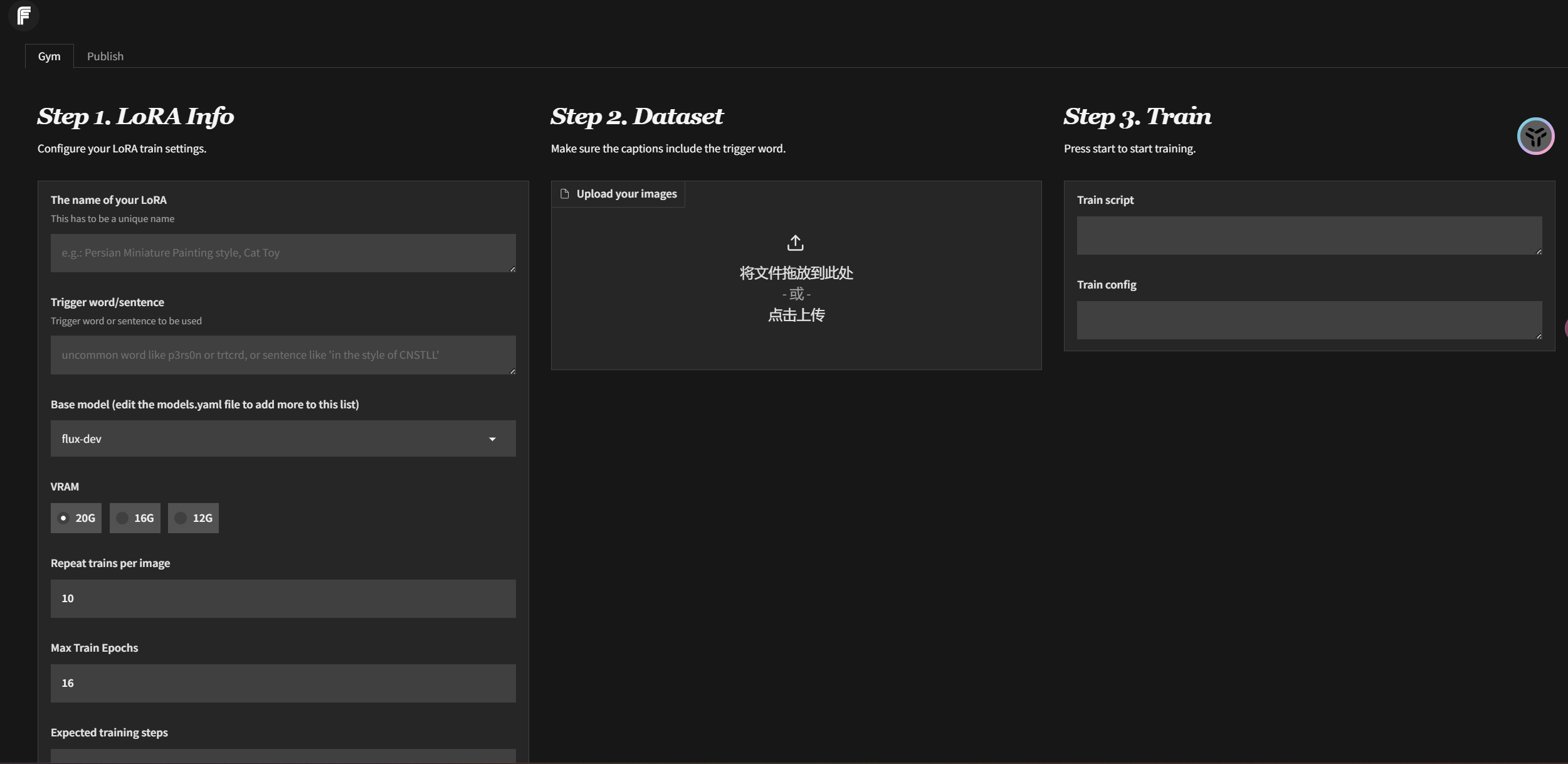
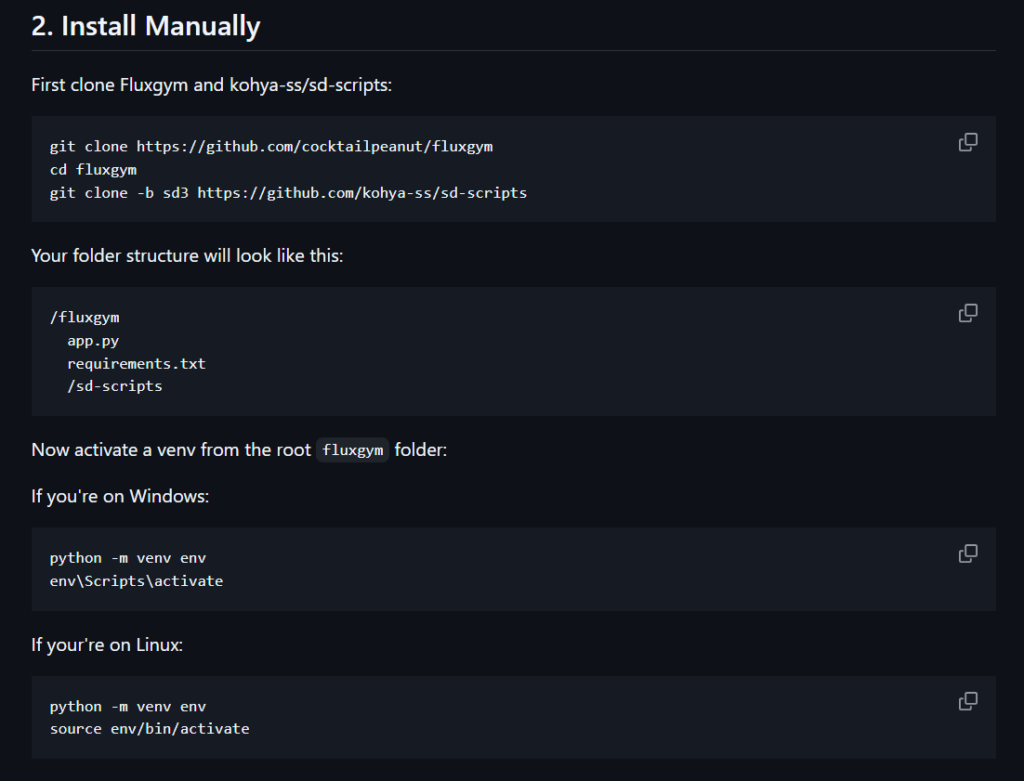
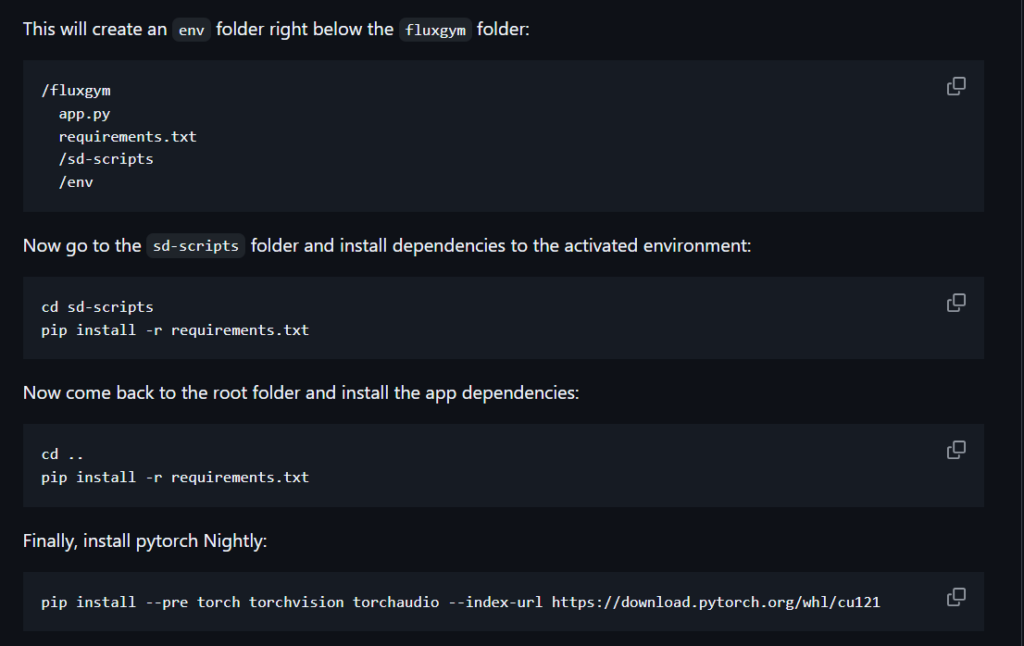
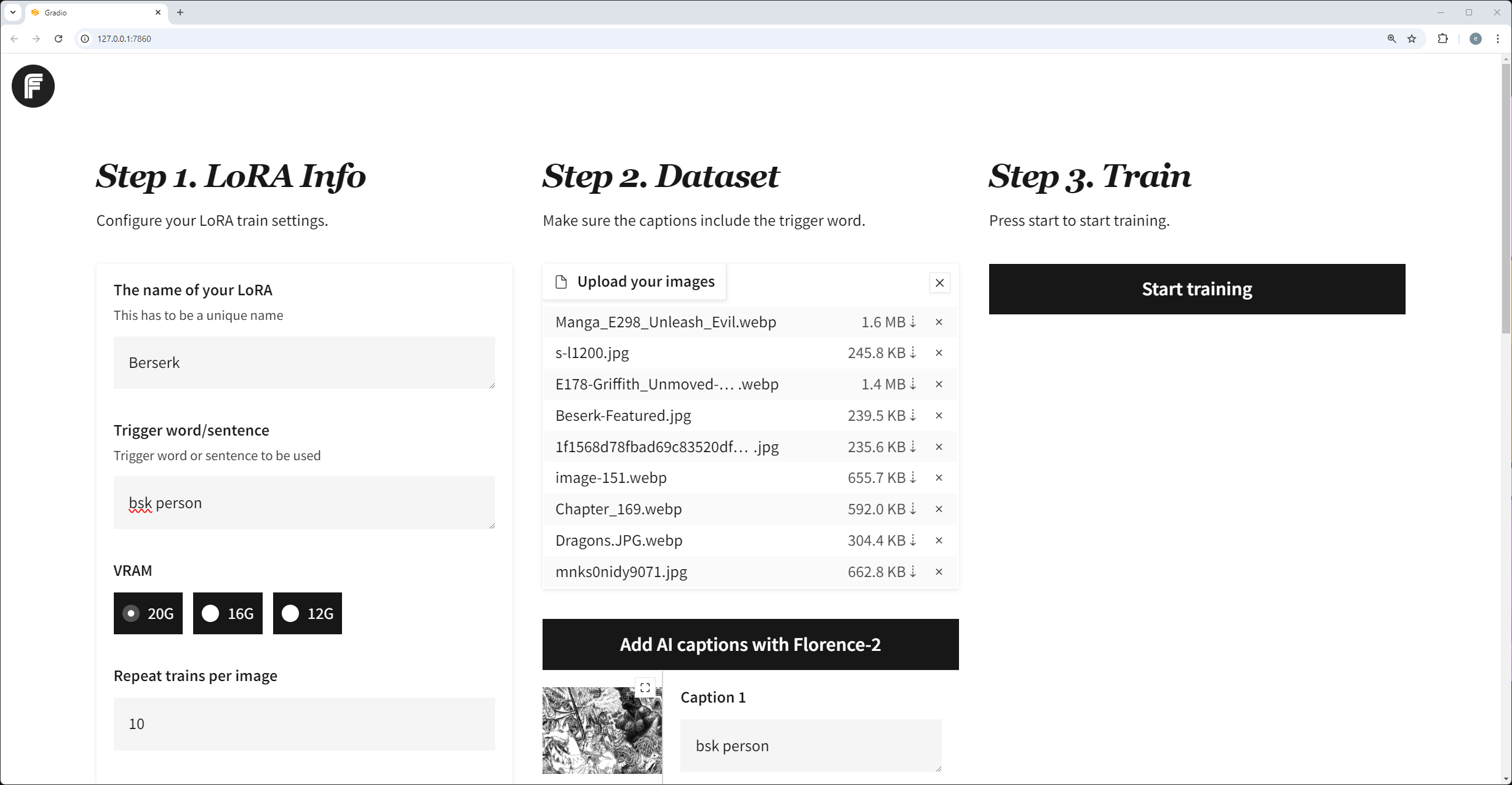
Pinokio是一个AI社区浏览器,它整合了很多AI工具及工作流。它的优势在于即使你是一个不懂编程语言的小白也能轻松配置好flux lora 的训练环境,安装好pinokio工具之后,直接在探索中找到fluxgym,即可一键安装,其中python环境、第三方依赖性、模型配置等等你完全不需要自行考虑。坐等它配置好就行。
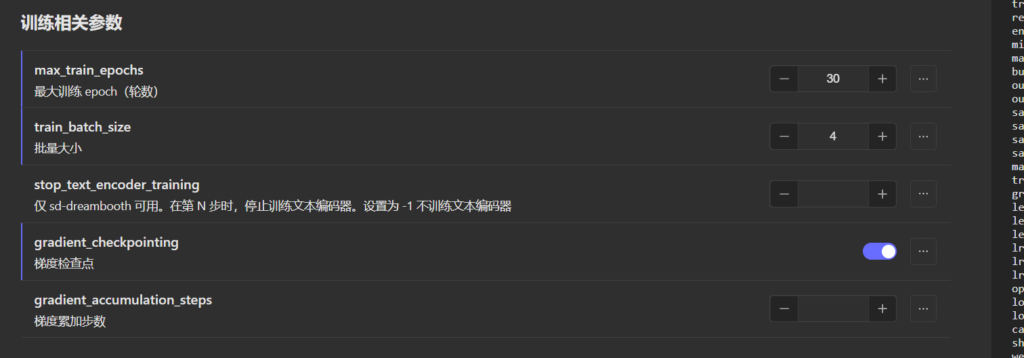
它底层基于Kohya Scripts开发,所有的参数设置都是统一的。在前端界面上采用三分法的布局设计,简化了操作步骤,123的布局设计让人一目了然,降低的理解门槛。在刚开始阶段,你都不需要详细了解具体的参数设置,只管提供优质的训练集就能拿到很好的模型效果,点赞。
实时的训练预览效果,它提供多种不同的预览图触发效果:
1.否定提示词
2.指定生成图像的宽度和宽度
3.指定生成图像的种子
4.指定生成图像的CFG比例
5.指定生成中的步骤数
支持显卡显存12G、16G、20G以上
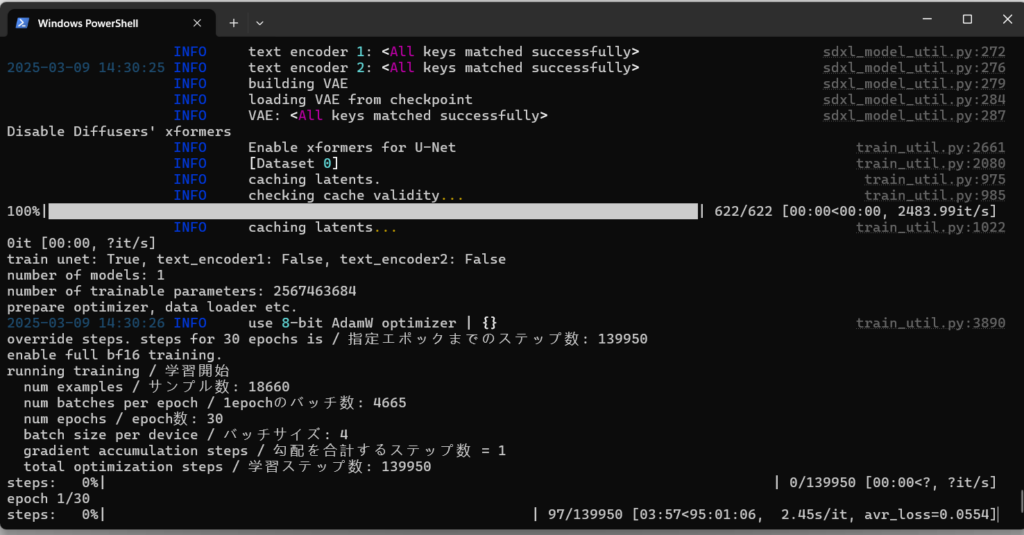
支持的底模:flux-dev、flux schnell、flux-dev2pro(实际上训练最好用flux-dev1.0、flux-dev2pro)
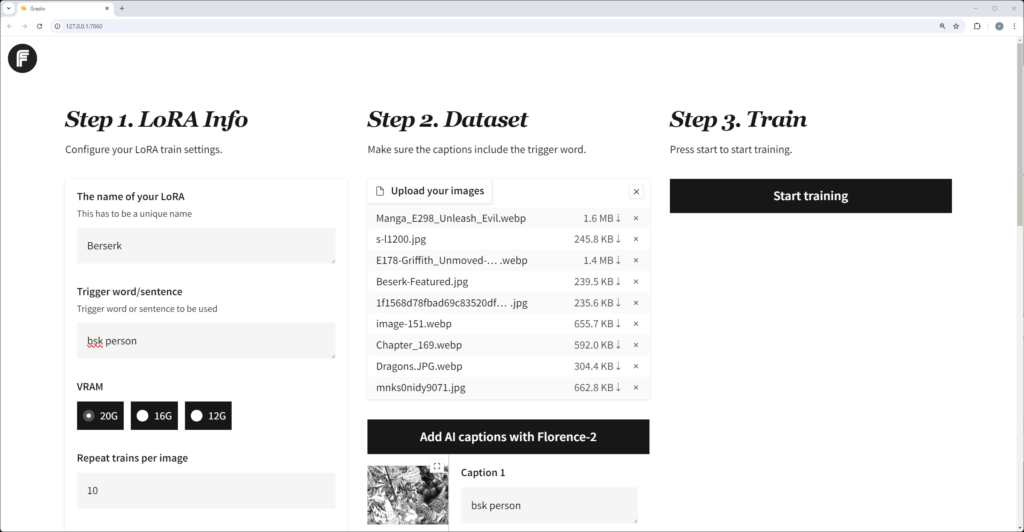
FluxGYM可以修改训练集的数量 app.py文件,将 MAX_IMAGES = 修改即可
import os
import sys
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
os.environ['GRADIO_ANALYTICS_ENABLED'] = '0'
sys.path.insert(0, os.getcwd())
sys.path.append(os.path.join(os.path.dirname(__file__), 'sd-scripts'))
import subprocess
import gradio as gr
from PIL import Image
import torch
import uuid
import shutil
import json
import yaml
from slugify import slugify
from transformers import AutoProcessor, AutoModelForCausalLM
from gradio_logsview import LogsView, LogsViewRunner
from huggingface_hub import hf_hub_download, HfApi
from library import flux_train_utils, huggingface_util
from argparse import Namespace
import train_network
import toml
import re
MAX_IMAGES = 650 //修改训练集数量
优点:远程训练, 面向专业级玩家、专业的UI界面
缺点:不稳定,需要简单的代码阅读能力,要配合ChatGpt或者deepseek使用
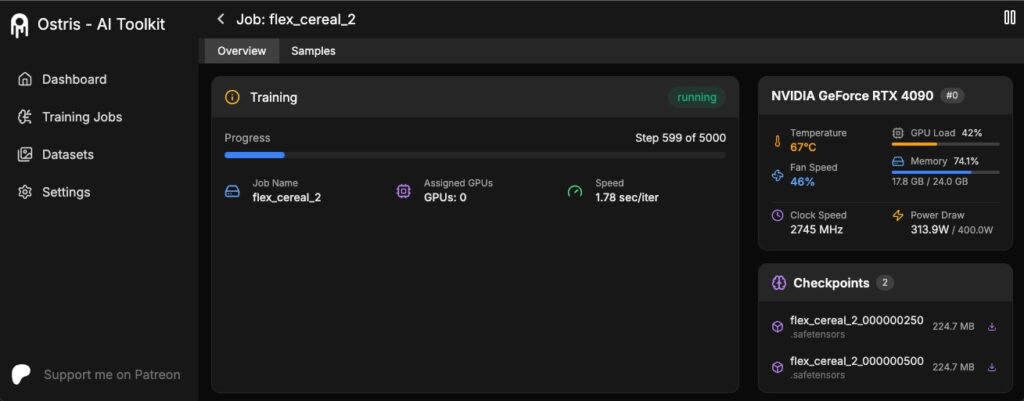
flux train-aitoolkit 目前处在一个早期版本,意味着在稳定性、功能可能不是那么的好用,该工具并非基于Kohya Scripts开发,其目录结构也和我见到的不同,因为自己对这块认识不够专业性,不便多说。
它最大的特点是基于huggingface远程访问的方式训练模型,这意味着你需要使用huggingface账户,从huggingface获取一个READ密钥,方可进行训练。
它支持FLUX.1-schnell、Flux-dev两个版本的模型训练,因为需要在本地预先写好模型配置信息,所以你需要一定的耐心来配置远程访问的信息。说实话,笔者在github上安装完这个工具都头大,你需要有一定的耐心和好奇心。否则很容易劝退。
 Screenshot
Screenshot
笔者在配置以上两个工具都遇到diffusers无法正常克隆的情况,所以你在配置这两个工具都要开启全局git代理,否则很大几率会克隆不成功报错。
如果依然报错请使用国内镜像:https://gitee.com/opensource-customization/diffusers
训练打标
flux的特性是基于自然语言描述打标,所以你在训练中请使用触发词和自然语言描述打标,这样在训练中能够得到很好的效果。这意味着你需要使用GPT、caption等模型工作流来处理你的训练集。笔者实际尝试过仅用tag来打标,发现训练效果并不好(基于秋叶lora-script)。
分辨率
flux对尺寸分辨率没有特殊要求,小到512、大到1024,768*1024也是可以的。
实际跑图
实际使用上,权重同样是0.7-0.9之间最好,并且是触发词加自然语言描述,你的描述越多,生成的效果越细节。这也意味着你在使用上需要对画面更具体的要求,甚至在想法没有那么具体的情况下需要借助deepseek这类工具给你提供帮助。