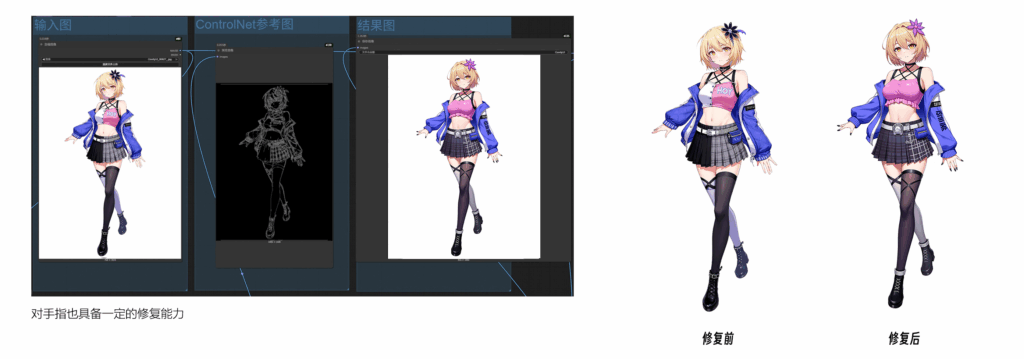
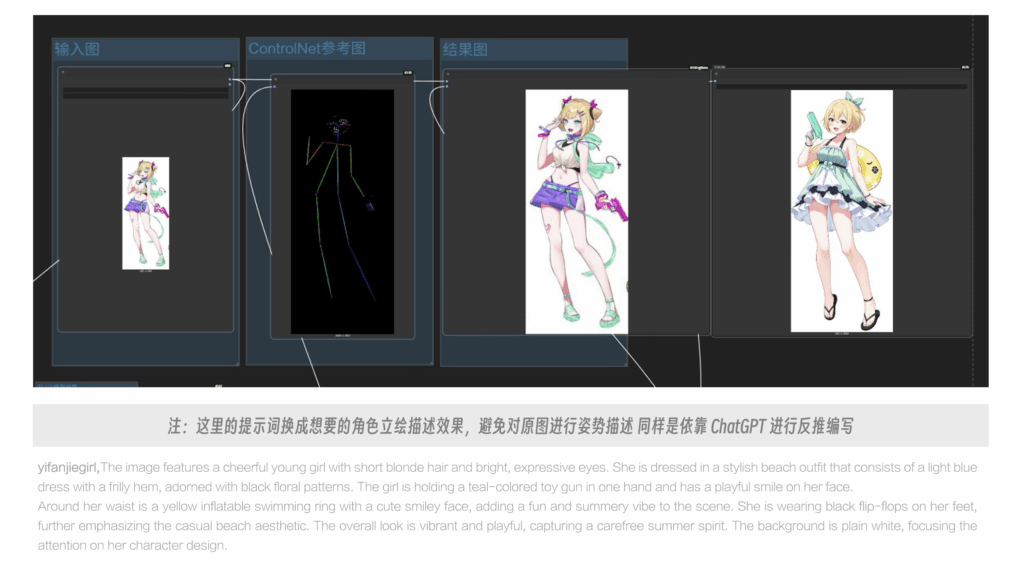
上周,我的一位做企业服务的朋友兴冲冲地给我演示他们公司刚上线的”革命性AI Agent产品”。
“你看,我们的智能体可以自动处理客户咨询!”他骄傲地点开界面。
我随口问了句:”如果客户问的问题超出预设范围呢?”
他愣了一下:”呃……那会转人工。”
“遇到多步骤复杂任务怎么办?”
“需要用户自己配置每一步流程。”
“那它和你们之前的聊天机器人有什么区别?”
长时间的沉默后,他尴尬地笑了:”好像……就是改了个名字?”
这不是个例。2025年11月,当Gartner将”代理式AI”(Agentic AI)列为十大技术趋势之首时,一场名为“Agent Washing”(智能体洗白)的行业乱象正在上演。
🎭 什么是”Agent Washing”?
简单来说,Agent Washing就是给产品换个”AI Agent”的马甲,但内核还是几年前的老技术。
就像:
- 奶茶店把”珍珠奶茶”改名叫”黑糖波波AI奶茶+”
- 健身房把”私教课”改名叫”AI智能体健身方案”
- 连卖煎饼果子的都想贴个”Agent”标签
Gartner研究总监闫斌一针见血地指出:
“目前多数所谓’Agent’实为’Agent Washing’,仅改名为Agent,而无实质升级。真正的AI Agent应具备感知、决策与行动的闭环能力,而目前大部分类似系统尚处初级阶段。”
说白了,现在市面上90%自称”AI Agent”的产品,其实都是”伪智能体”。
💰 为什么突然冒出这么多”假Agent”?
1. 市场疯了——2029年市场规模达50%
数据太诱人了:
- Gartner预测,到2029年,代理式AI将占全球AI总投资的近50%
- 投资人见面第一句话:”你们有Agent吗?”
- 客户招标文件里必写:”要求具备智能体能力”
不贴个”Agent”标签,连PPT都做不下去。
2. 技术门槛太高——真Agent不是谁都能做
构建真正的AI Agent需要:
- 强大的大模型基础(OpenAI o3、Claude 4那种级别)
- 复杂的多智能体协作框架
- 可靠的工具调用和环境交互能力
- 完善的错误处理机制
这套技术栈的研发成本动辄数千万美元。
中小企业怎么办?改个名呗,反正市场定义也不清晰。
3. 定义模糊——谁也说不清什么算Agent
问10个专家”什么是AI Agent”,你会得到10个答案:
- 有人说:”能自主决策就是Agent”
- 有人说:”能调用工具就是Agent”
- 有人说:”带个对话界面就是Agent”
定义越模糊,浑水摸鱼的空间就越大。
🔍 如何识别”假Agent”?五个问题见真章
别被营销话术忽悠,问这五个问题:
问题1:”它能处理没见过的新情况吗?”
真Agent:
- 用户:”帮我订周末团建的餐厅”
- Agent:自动查询天气→分析团队饮食偏好→筛选合适餐厅→比较价格→预订
假Agent:
- 用户:”帮我订周末团建的餐厅”
- Agent:”请选择:1.中餐 2.西餐 3.日料”(还是填表那一套)
问题2:”遇到错误会怎么办?”
真Agent:
订票失败→自动尝试其他平台→价格不合适就换方案→都不行就联系人工
假Agent:
订票失败→弹出错误提示:”操作失败,请重试”(然后就没有然后了)
问题3:”能自己规划多步骤任务吗?”
真Agent:
- 给个目标:”组织一场50人的产品发布会”
- Agent自动拆解:选场地→设计流程→邀请嘉宾→准备物料→媒体宣传……
假Agent:
- 需要你手动设置:”步骤1:xxxx,步骤2:xxxx……”
- 它只是按你的脚本执行,改一个环节就全乱套
问题4:”有记忆和学习能力吗?”
真Agent:
- 记住你上次说”不喜欢香菜”
- 这次订餐自动备注”不要香菜”
- 还会推荐更适合你口味的餐厅
假Agent:
- 每次都像第一次见面
- 重复问同样的问题
- 没有任何个性化
问题5:”能跨平台、跨工具协同吗?”
真Agent:
从企业微信查任务→到钉钉发通知→去飞书找文档→调用Office生成报告
假Agent:
只能在自己的系统里转悠,出了这个软件就抓瞎
⚖️ 真假对比:一个案例说明一切
让我们用一个真实场景对比真假Agent的差异:
任务:帮我安排下周出差到上海的行程
假Agent(实际上是规则引擎+API调用)
对话:
- 用户:”帮我安排下周出差到上海”
- 假Agent:”请选择出发日期”
- 用户:”下周三”
- 假Agent:”请选择返程日期”
- 用户:”下周五”
- 假Agent:”已为您找到3趟航班,请选择……”
- 用户:”最便宜的”
- 假Agent:”请选择酒店……”
特点:
- ❌ 一问一答,像填表一样
- ❌ 不会主动思考
- ❌ 不考虑你的偏好和特殊需求
- ❌ 出了差错就卡住
真Agent(具备感知、决策、行动能力)
对话:
- 用户:”帮我安排下周出差到上海”
- 真Agent:”好的!我看到你下周三上午10点有个重要会议,建议周二晚上出发,这样时间更从容。我查了天气预报,那几天上海有雨,已经在你的行李清单里加了雨伞提醒。”
自动执行:
- 感知环节:
- 分析日历发现周三有会
- 查询天气预报
- 回忆你上次出差说过”不喜欢赶早班飞机”
- 检查你的差旅预算
- 决策环节:
- 制定方案:周二下午出发
- 选择航班:不是最便宜但时间最合适的
- 酒店选择:会议地点步行10分钟内
- 预留备用方案:万一航班延误怎么办
- 行动环节:
- 订票、订酒店
- 自动填写报销单
- 在日历里创建提醒
- 发航班信息给秘书
- 遇到订票失败自动换方案
特点:
- ✅ 理解上下文和隐含需求
- ✅ 主动规划完整方案
- ✅ 考虑个人偏好
- ✅ 具备应变能力
Gartner的预警:泡沫即将破裂
在2025年的技术成熟度曲线上,AI Agent正处于一个危险的位置:
当前阶段:期望膨胀期顶峰(Peak of Inflated Expectations)
这意味着什么?
短期(2025-2026):泡沫继续膨胀
- 更多”伪Agent”产品涌现
- 营销话术越来越夸张
- 客户试用后发现”货不对板”
- 市场信任度开始下降
中期(2027-2028):泡沫破裂低谷期
- 伪Agent企业批量倒闭或转型
- 投资人和客户变得谨慎
- 行业标准和评测体系建立
- 真正有技术实力的企业脱颖而出
长期(2029+):稳步爬升期
- 成熟的Agent产品占据主流
- 形成健康的商业生态
- 真正实现50%投资占比的预测
历史总在重复:
- 2017年的”区块链洗白”
- 2019年的”大数据洗白”
- 2023年的”大模型洗白”
- 2025年的”Agent洗白”
每一次技术浪潮都会经历这个过程。
🌟 哪些才是真正的好产品?
国际标杆
1. Anthropic Claude “Computer Use”
- 能力:真正能”看懂”电脑屏幕,控制鼠标键盘操作软件
- 应用:自动填写表单、处理邮件、生成报告
- 评价:这才是从”理解世界”到”操作世界”的跨越
2. OpenAI o3
- 能力:在ARC-AGI复杂推理测试中达到87%准确率
- 特点:能系统性分解多步骤任务,具备真正的推理能力
- 意义:从”感知智能”到”行动智能”的里程碑
3. Google DeepMind AlphaFold
- 能力:自主预测蛋白质结构,已帮助科学家解决数千个难题
- 特点:不需要人工干预,自己规划实验和验证
- 影响:推动生物医学研究进入新时代
国内优秀案例
1. 月之暗面Kimi K2 Thinking
- 能力:长文本理解+多步推理
- 特点:能真正”思考”而不是简单匹配
- 战略:开源生态的重要补充
2. 阿里通义Agent
- 应用:企业场景的复杂流程自动化
- 案例:电商客服、物流调度、供应链优化
- 优势:深度整合阿里生态
3. 字节豆包Agent
- 能力:多工具调用+任务分解
- 场景:内容创作、数据分析、运营自动化
- 特色:结合字节的内容理解优势
💡 给你的三个建议
如果你是企业主
别急着追风口:
- 不要看到”Agent”就兴奋
- 深入了解技术实现
- 要求看实际demo而非PPT
- 试用期多测试边界场景
务实选择:
- 先解决真实问题,再谈概念
- 可能一个传统RPA就够用了
- 不需要为”Agent”标签付溢价
如果你是开发者
扎实积累技术:
- 不要盲目跟风改名
- 专注核心能力建设
- 真正实现感知-决策-行动闭环
- 参考开源框架(AWS Multi-Agent、NVIDIA NIM)
长期主义:
- 泡沫破裂后才是真正机会
- 技术积累需要时间
- 好产品终将胜出
如果你是投资人
保持理性判断:
- 不要被营销话术迷惑
- 深入调研技术团队背景
- 关注实际落地案例
- 参考Gartner等权威机构评估
识别真伪:
- 要求现场演示复杂场景
- 观察错误处理能力
- 评估团队的技术积累
结语:泡沫之后,才见真金
2025年的AI行业,正在经历一场”Agent狂欢”。
有人真心在做技术突破,有人只是在蹭热点。
市场会用最残酷的方式给出答案:
- 真正有价值的产品会沉淀下来
- 徒有虚名的”伪Agent”终将消失
- 用户会用脚投票
就像Gartner技术成熟度曲线所揭示的:
每一次技术浪潮,都要经历膨胀、破裂、爬升三个阶段。
我们现在正处于”膨胀期顶峰”,泡沫破裂不可避免。
但这并不可怕。
真正的创新者,会在泡沫破裂后的废墟上,建立起新的秩序。
问题来了:你遇到过哪些”伪Agent”产品?在评论区说说你的经历吧!
参考资料:
- Gartner《2025年中国数据、分析和人工智能技术成熟度曲线》
- 闫斌(Ben Yan),Gartner高级研究总监访谈
- 《2025 AI大模型开发生态白皮书》




















![[迭代] Vue 框架搭建 Gemini-nano-banana 支持图像比例输出](https://trilightlab.com/wp-content/uploads/2025/10/Screenshot-2025-10-09-215911-1568x636.png)
![[迭代] 我用 Vue 框架搭建 Gemini-nano-banana](https://trilightlab.com/wp-content/uploads/2025/09/Dingtalk_20250925201030-1568x934.jpg)