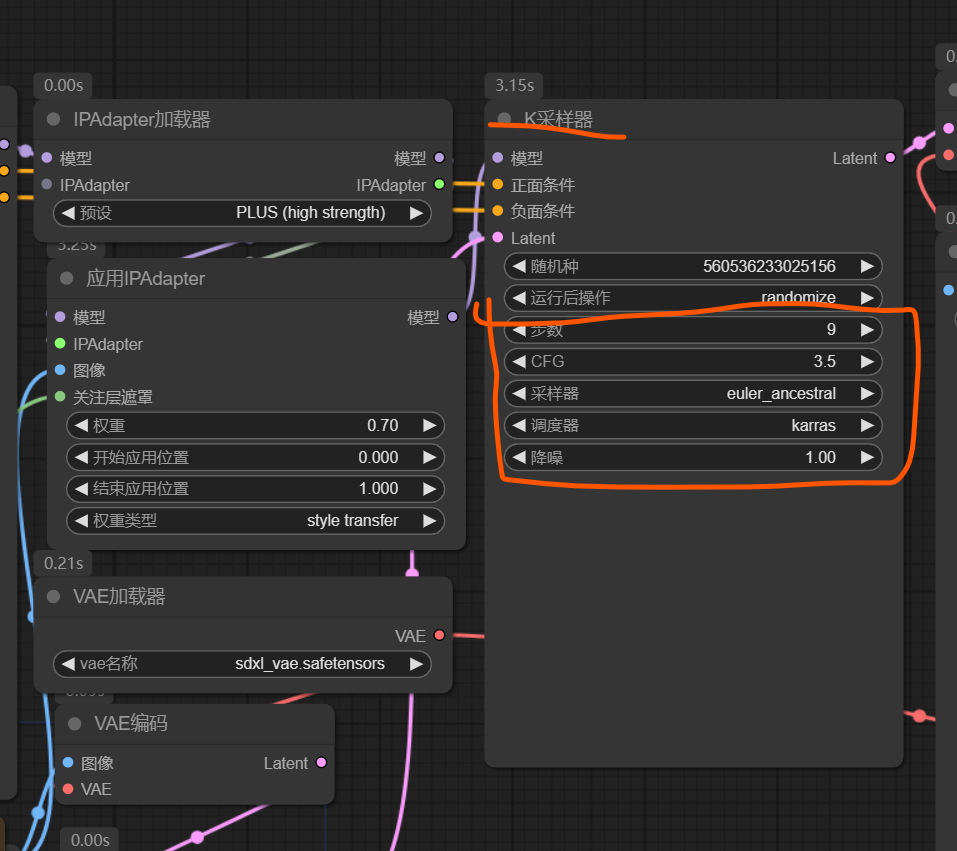
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\nodes.py", line 1993, in load_custom_node
module_spec.loader.exec_module(module)
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\custom_nodes\comfyui_face_parsing\__init__.py", line 18, in <module>
download_url("https://huggingface.co/jonathandinu/face-parsing/resolve/main/config.json?download=true", face_parsing_path, "config.json")
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\site-packages\torchvision\datasets\utils.py", line 134, in download_url
url = _get_redirect_url(url, max_hops=max_redirect_hops)
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\site-packages\torchvision\datasets\utils.py", line 82, in _get_redirect_url
with urllib.request.urlopen(urllib.request.Request(url, headers=headers)) as response:
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\urllib\request.py", line 216, in urlopen
return opener.open(url, data, timeout)
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\urllib\request.py", line 519, in open
response = self._open(req, data)
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\urllib\request.py", line 536, in _open
result = self._call_chain(self.handle_open, protocol, protocol +
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\urllib\request.py", line 496, in _call_chain
result = func(*args)
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\urllib\request.py", line 1391, in https_open
return self.do_open(http.client.HTTPSConnection, req,
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\urllib\request.py", line 1351, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。>
Cannot import D:\ComfyUI-aki\ComfyUI-aki-v1.3\custom_nodes\comfyui_face_parsing module for custom nodes: <urlopen error [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。>
FizzleDorf Custom Nodes: Loaded
FaceDetailer: Model directory already exists
FaceDetailer: Model doesnt exist
FaceDetailer: Downloading model
ef get_restorers():
models_path = os.path.join(models_dir, "facerestore_models/*")
models = glob.glob(models_path)
models = [x for x in models if (x.endswith(".pth") or x.endswith(".onnx"))]
if len(models) == 0:
fr_urls = [
"https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/GFPGANv1.3.pth",
"https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/GFPGANv1.4.pth",
"https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/codeformer-v0.1.0.pth",
"https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/GPEN-BFR-512.onnx",
"https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/GPEN-BFR-1024.onnx",
"https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/GPEN-BFR-2048.onnx",
]
for model_url in fr_urls:
model_name = os.path.basename(model_url)
model_path = os.path.join(dir_facerestore_models, model_name)
download(model_url, model_path, model_name)
models = glob.glob(models_path)
models = [x for x in models if (x.endswith(".pth") or x.endswith(".onnx"))]
return models
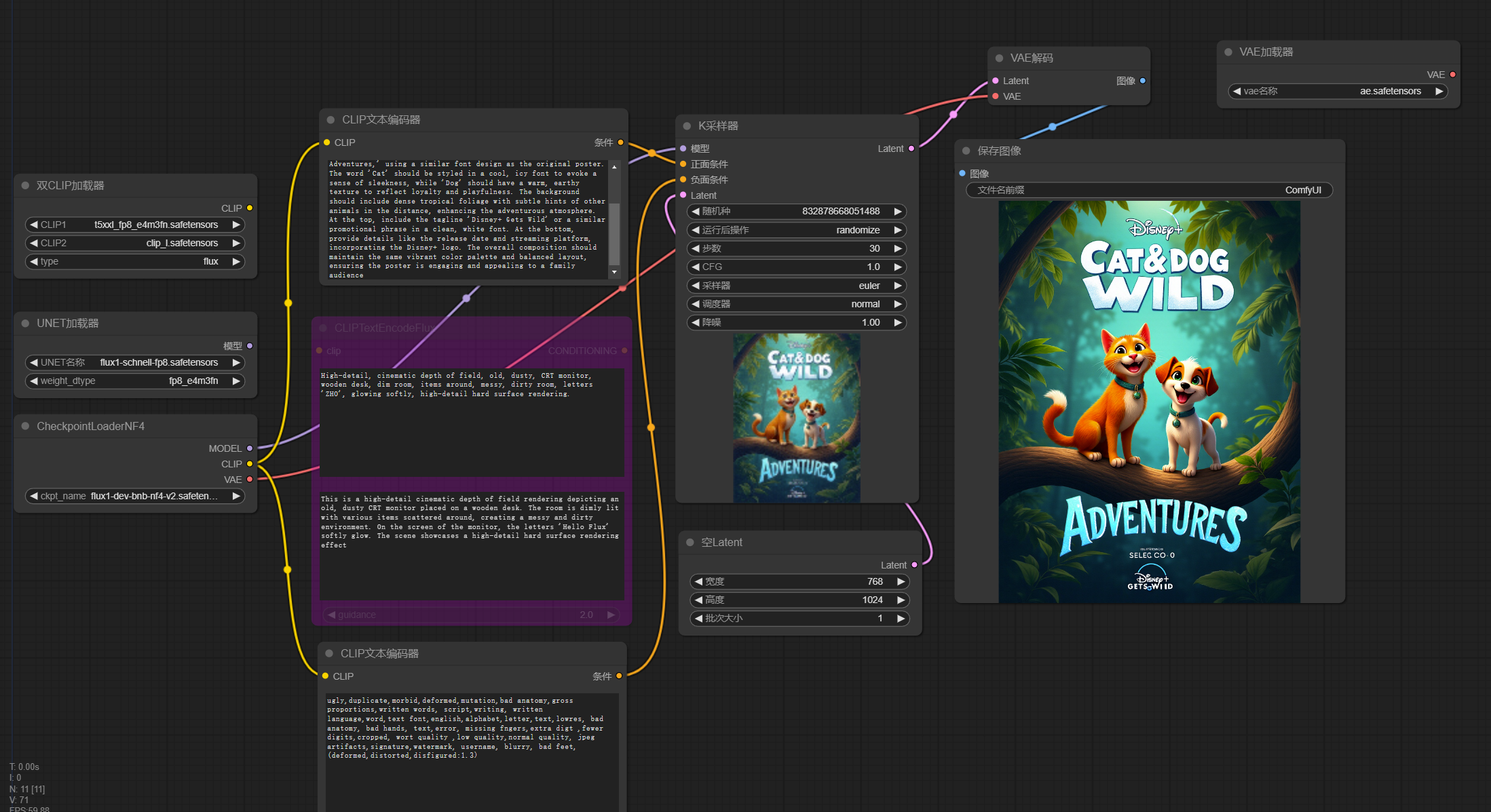
获得关键词如下:This is a digital promotional poster for the Disney+ animated film “The Ice Age Adventures of Buck Wild.” The image is a vibrant, colorful cartoon depiction set in a lush, jungle-like environment. The background features dense foliage, tall trees with broad leaves, and a variety of greenery, creating a sense of depth and immersion.
In the foreground, two anthropomorphic ground sloths, Buck and Crash, are prominently featured. They are standing on a large, gnarled tree branch, with Buck on the left and Crash on the right. Buck is holding a stick in his right hand and has a playful expression, while Crash is smiling and has his arms outstretched, as if excited. Both characters have light brown fur with darker brown stripes, and their eyes are large and expressive.
The title “The Ice Age Adventures of Buck Wild” is prominently displayed in large, bold, yellow letters in the center of the poster. Above the title, the text “Disney+ + gets wild” is written in white. Below the title, the Disney+ logo is visible, along with the phrase “Original movie from 20th Century Studios.” The poster’s overall style is bright and cheerful, with a playful, adventurous tone.
提示词如下:This image is a digital illustration, likely created in a comic book style, featuring a futuristic, cyberpunk aesthetic. The central figure is a young woman with pale blue skin and striking, large, orange eyes. Her hair is platinum blonde and styled in a sleek, high ponytail. She is dressed in a high-tech, form-fitting outfit with metallic accents, giving her a futuristic, robotic appearance. Her left hand, which is gloved in a black, mechanical-looking glove, is holding a clear glass filled with a refreshing drink, which she is sipping through a straw.
The background is predominantly black, with vibrant yellow and orange accents, creating a striking contrast that highlights the central figure. The magazine cover title, “FAVR,” is prominently displayed in large, bold letters at the top, with additional Japanese text on the left side. The word “SMOOTHIE” is written in bold, white letters at the bottom, emphasizing the theme of the cover. The overall color palette is a mix of cool blues and warm oranges, contributing to the high-tech, futuristic vibe of the artwork. The image is detailed, with a focus on the woman’s expressive face and the sleek, futuristic design of her outfit.