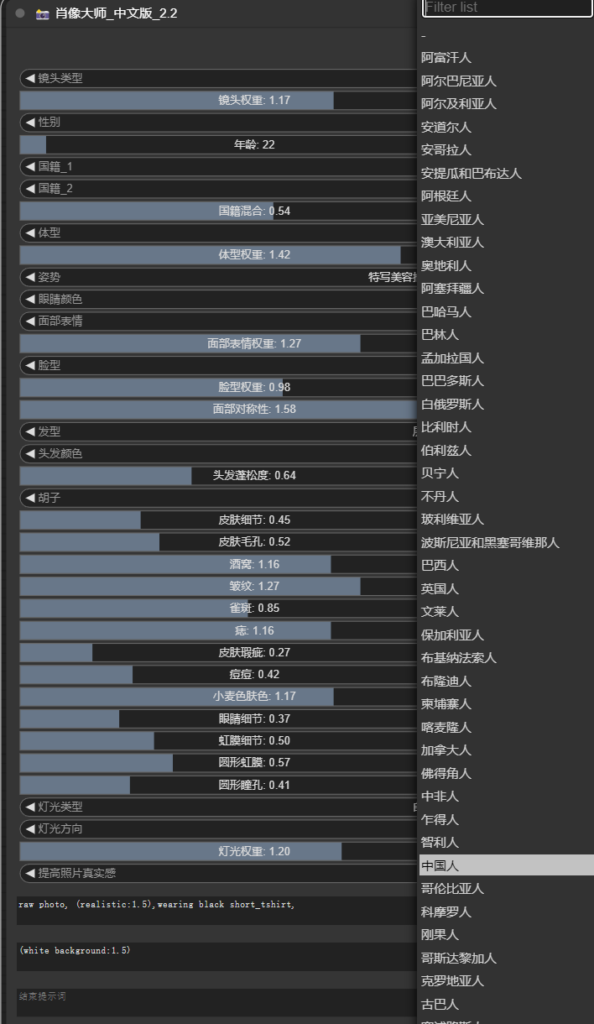
这个模型基于flux-dev版模型训练的lora,具备很好的泛化能力。二次元风格,这个模型可以结合线稿、参考姿势结合union-controlnet-v2模型一起使用,能够很好的控制造型姿势。
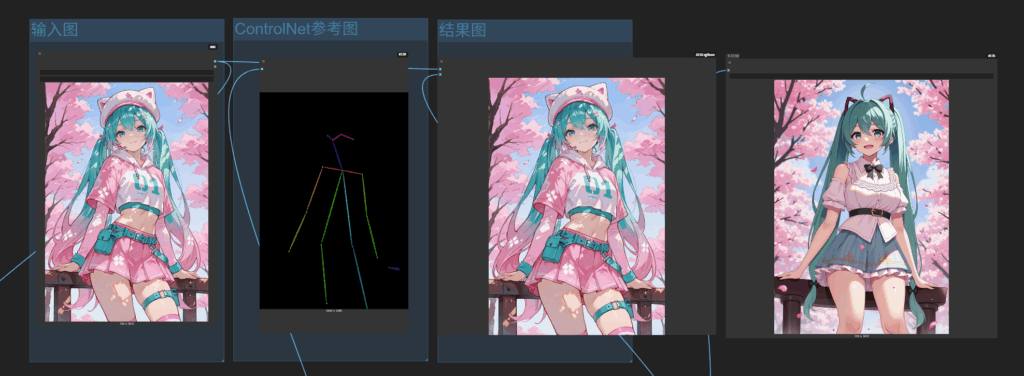
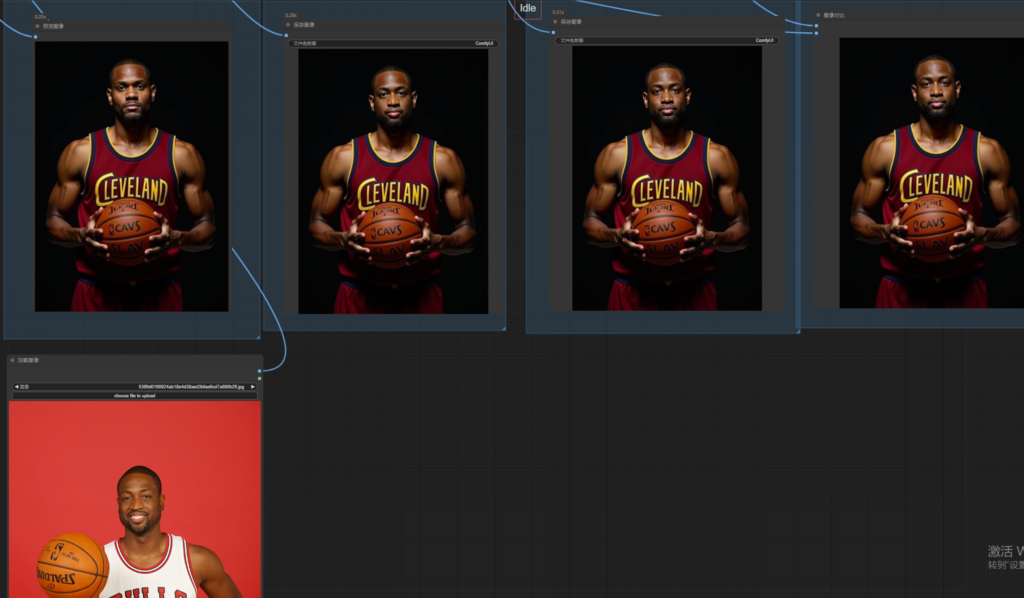
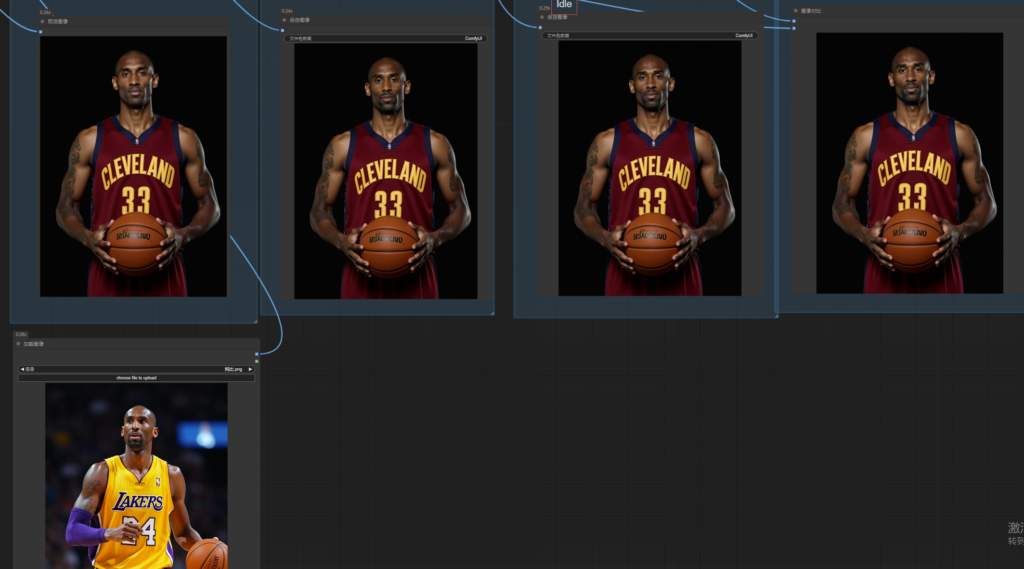
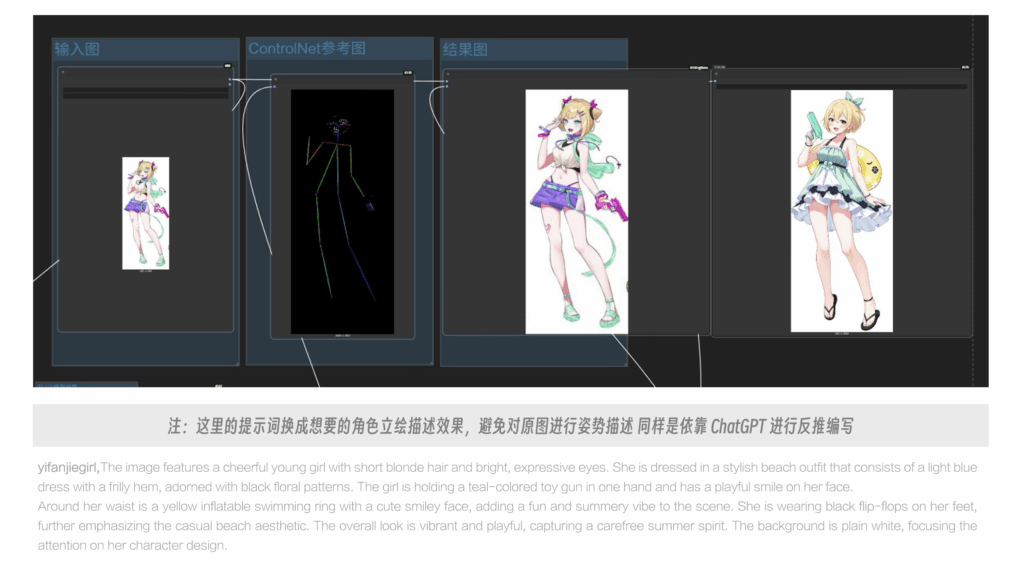
图1是参考图,图3是结合姿势生成的效果。
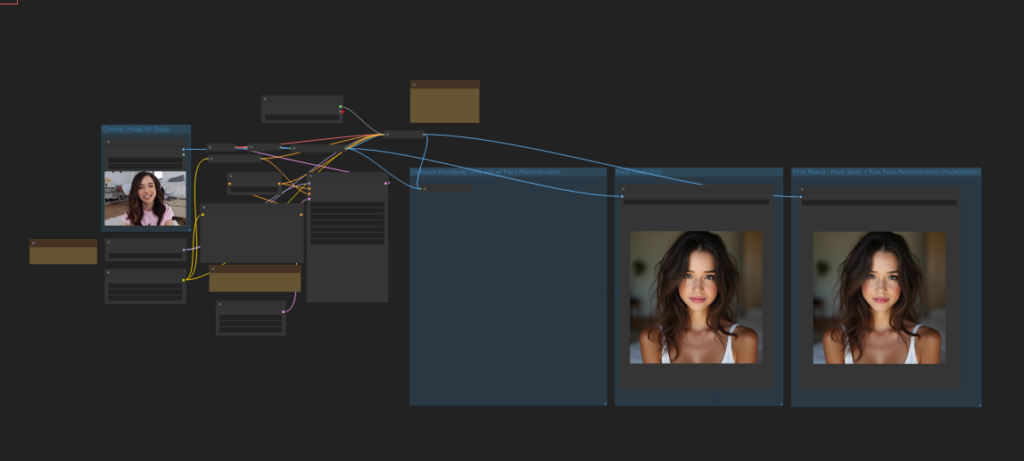
下面两张图是完全通过参考姿势,完全由模型生成的效果,最终在ps中进行合成构图。


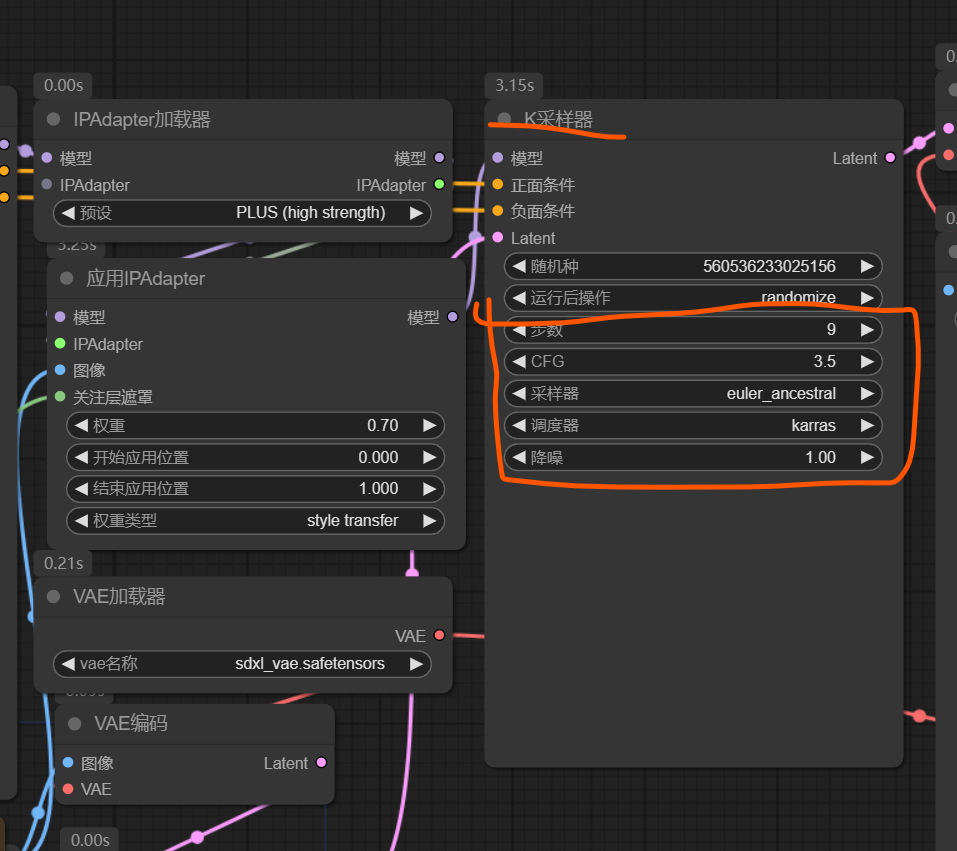
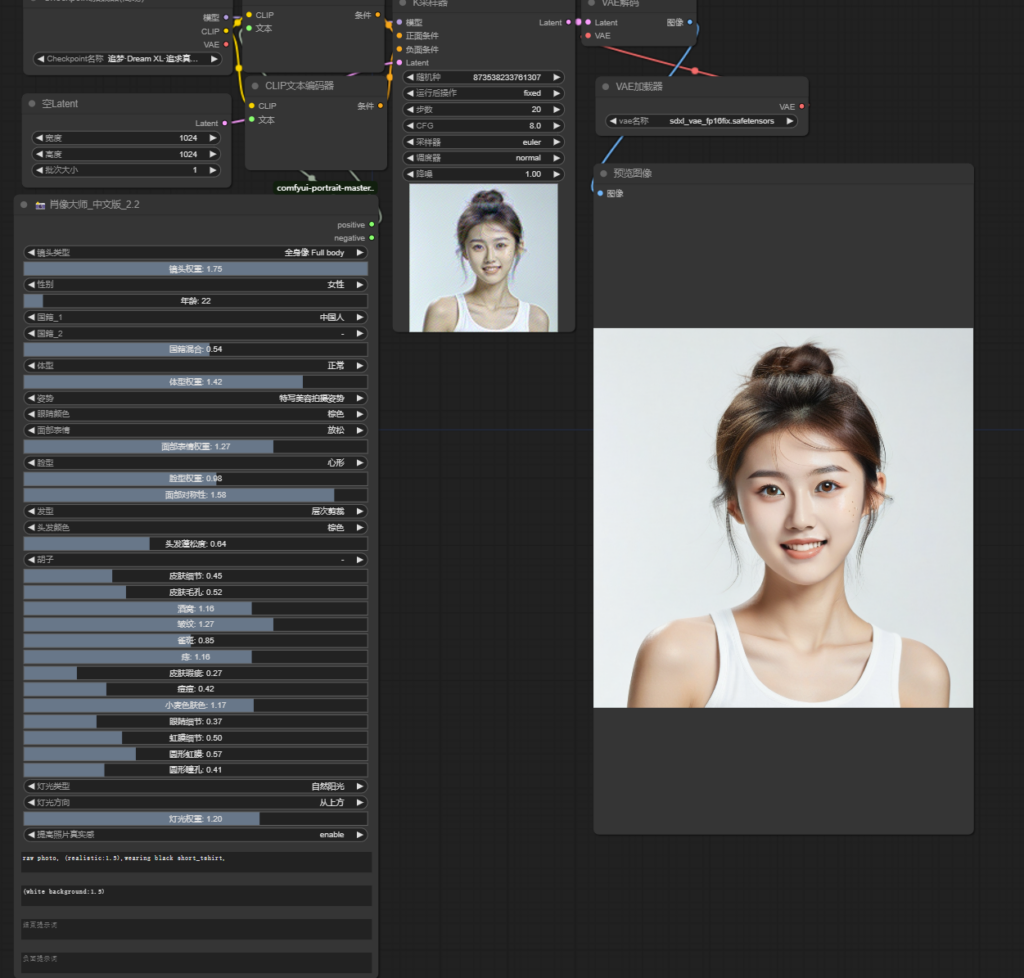
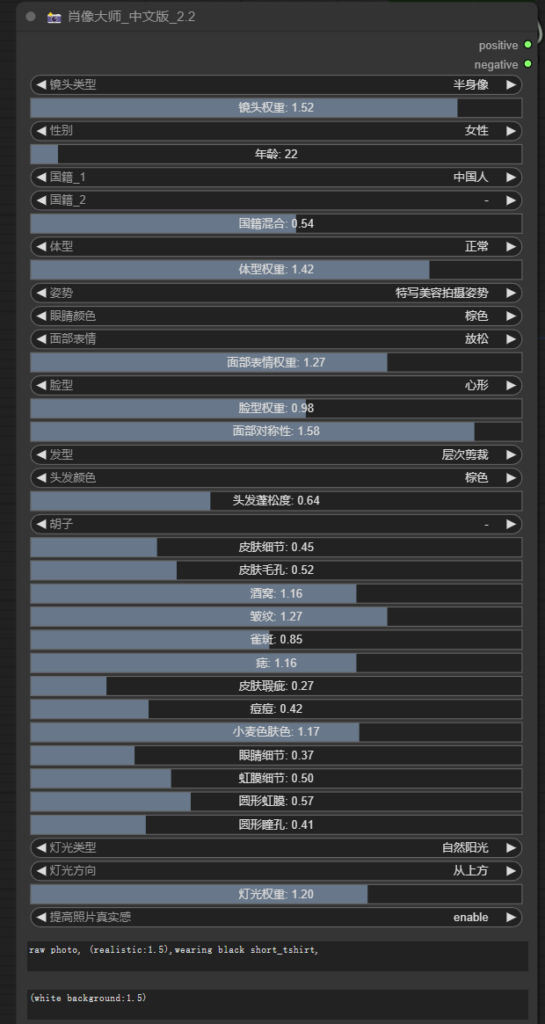
训练参数
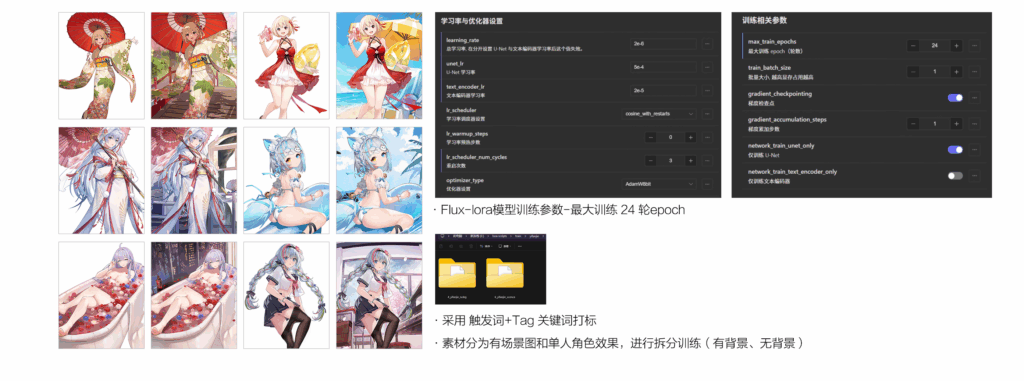
最大训练24轮,打标采用触发词和tag组合,素材分为场景图和单人角色效果,拆分训练
下图为文生图效果:

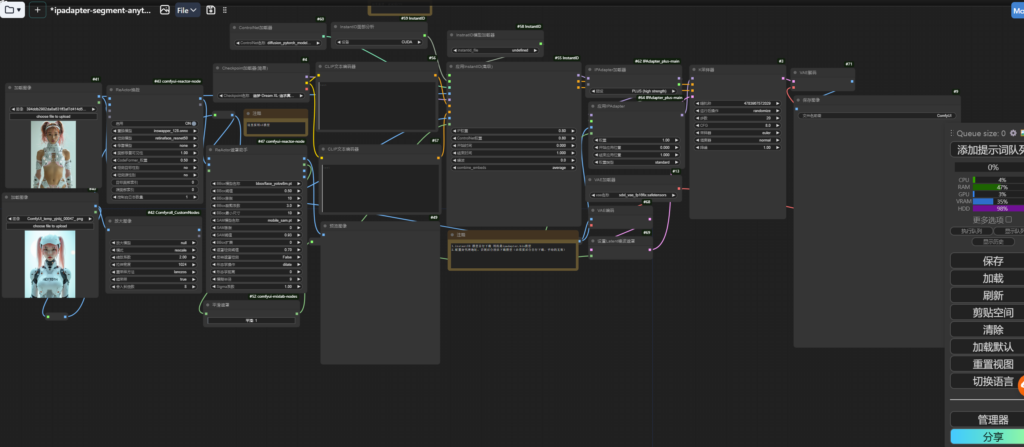
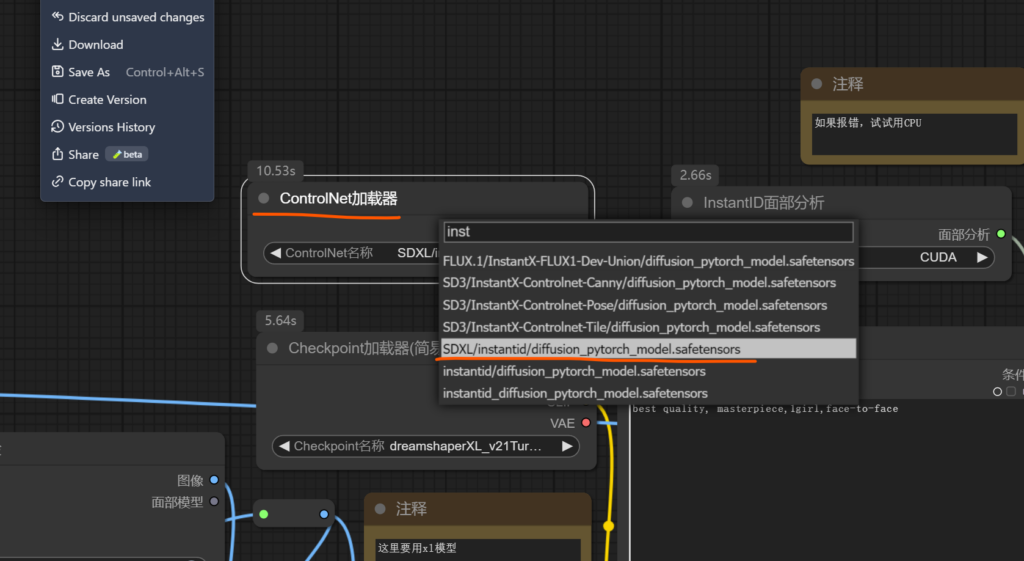
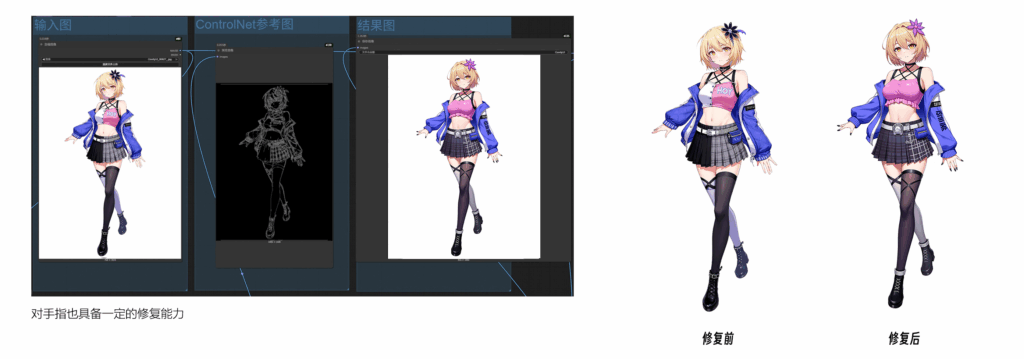
以下是lora通过controlnet-v2 一起使用的流程效果,包括最终修复的效果。




通过网盘分享的文件:
模型触发词:yifanjie_girl,后续接自然文本描述 lora模型权重建议在0.7-0.9之间
链接: https://pan.baidu.com/s/1PQi21XKcrFCvjroZoJXSTQ?pwd=3f54 提取码: 3f54
配套的union-controlnet-v2工作流:https://huggingface.co/Shakker-Labs/FLUX.1-dev-ControlNet-Union-Pro-2.0