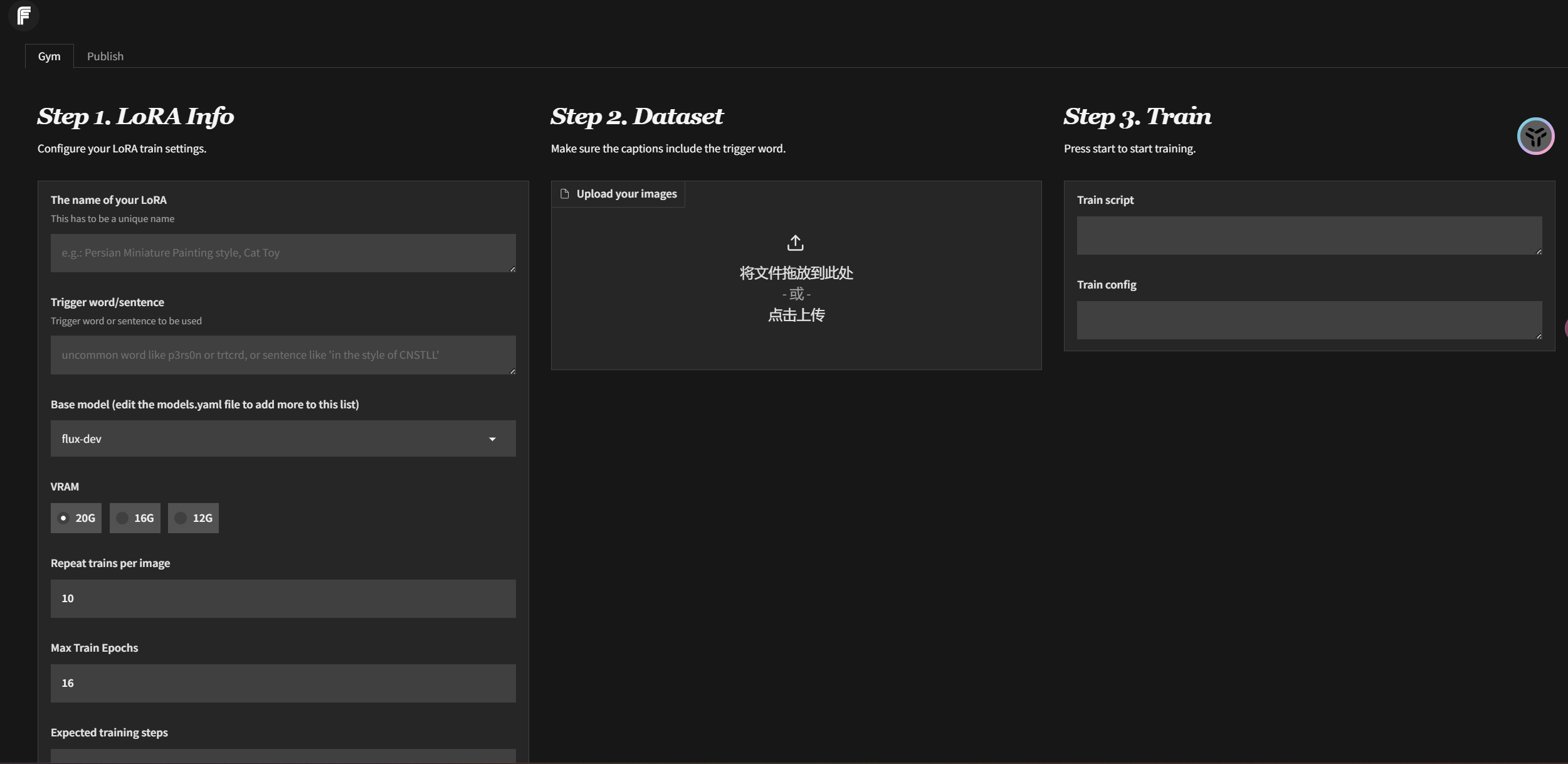
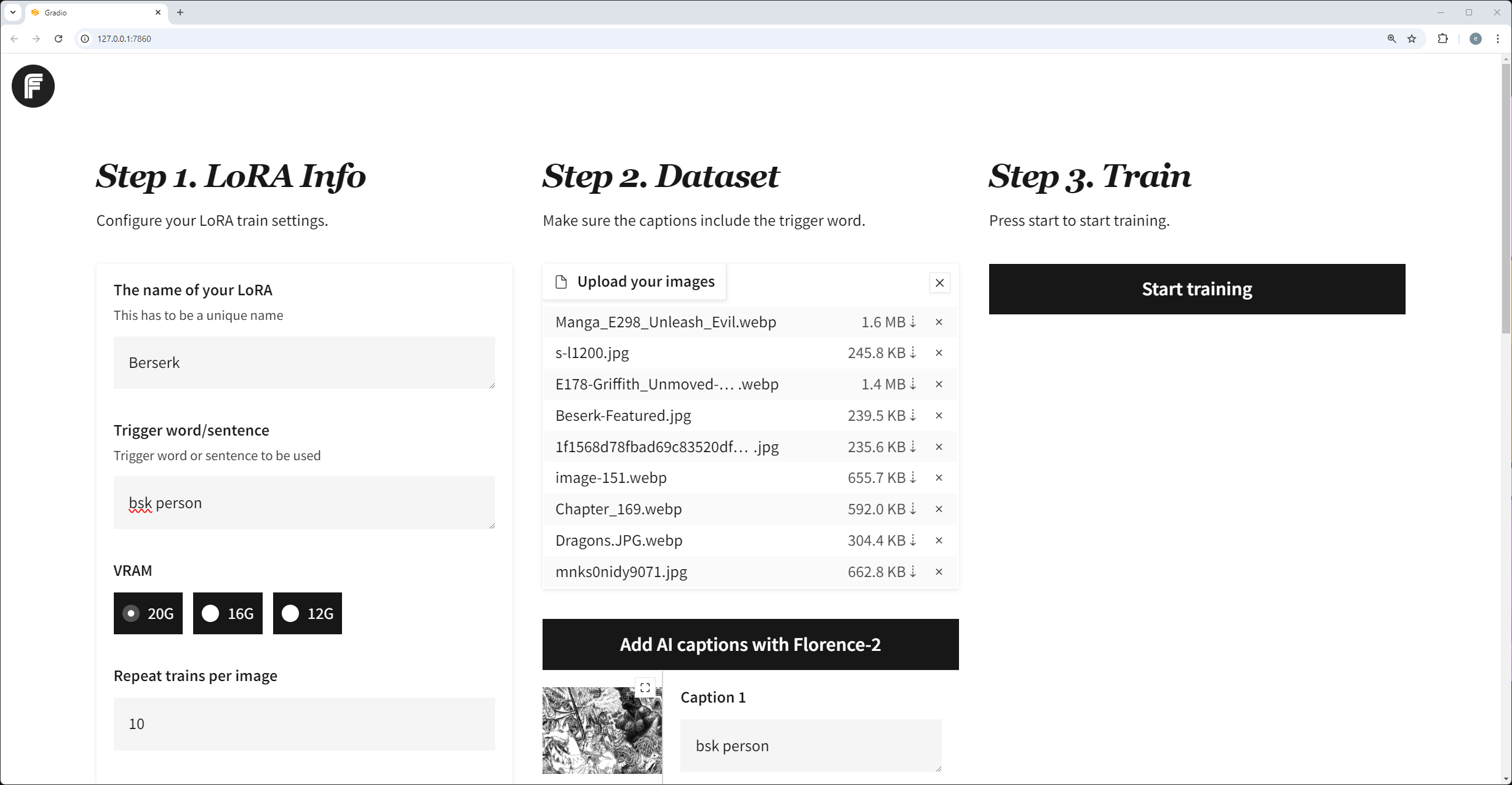
The intent of generating images for my purposes is always central to creating a feeling; however, using machine learning to create images presents the problem of control. Image outputs can be random, incoherent, and difficult to fine-tune for small textural renditions. Feeling and aesthetics are related; to be able to create a feeling with intent, the aesthetic has to be controllable. There are ways to control aesthetics with prompting, custom nodes, and sampling settings, but the most effective approach starts near the beginning of the model pipeline—with custom-trained LoRAs. When training a LoRA, I encounter a long list of complex ML terminology that only registers as abstract concepts within my camera-based foundational understanding of image creation. This research is conducted to help myself and the open-source community define and visualize the effects these parameters have on imagery.
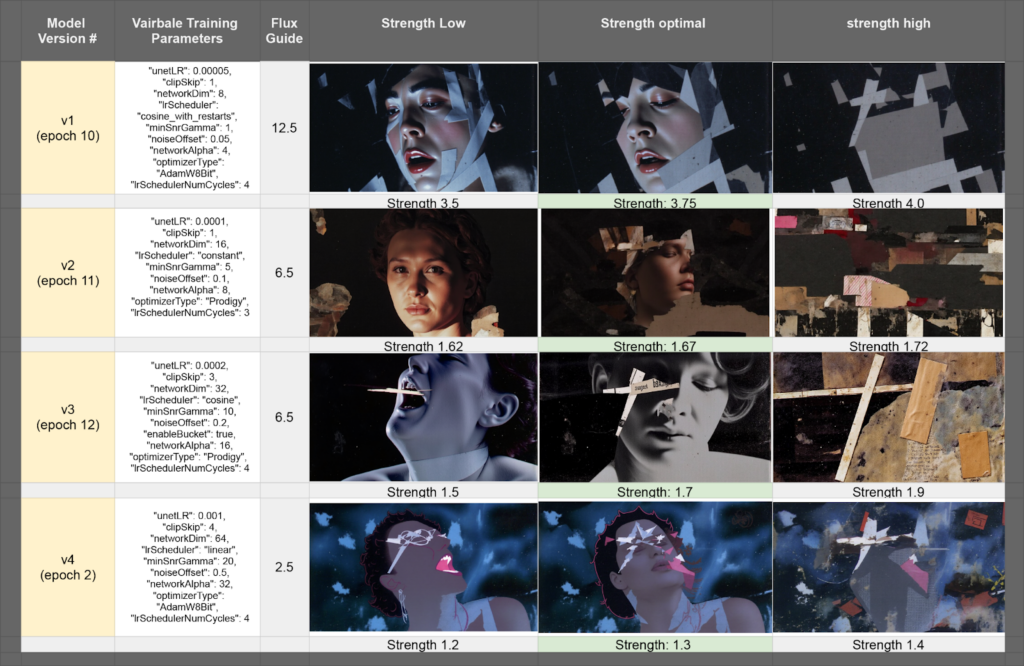
I created a dataset of 30 images generated by Kurt Schwitters, an early 1900s Dadaism artist, intending to synthesize his noninformative collage style into controlled imagery with formative subject matter. I trained four different LoRAs, each with a different combination of parameters at extreme variations, to compare the results. Because the training data is all abstract collage and I want to merge the style with defined forms, I labeled all of the training data with false captions, covering a range of scene descriptions. The training data is available here. 我创建了一个由20世纪初达达主义艺术家库尔特·施维特斯(Kurt Schwitters)生成的30幅图像的数据集,打算将他的非信息拼贴风格合成为具有形成主题的受控图像。我训练了四个不同的LoRA,每个LoRA在极端变化下具有不同的参数组合,以比较结果。因为训练数据都是抽象的拼贴画,我想将样式与定义的形式合并,所以我用假标题标记了所有训练数据,覆盖了一系列场景描述。训练数据可在此处获取。
1.1 Parameters tested 验证参数
Unet Learning Rate Unet学习率
Clip Skip 剪辑跳过
Network Dimension 网络维度
Learning Rate Scheduler 学习率
Min SNR Gamma 最小SNR Gamma
Noise Offset 噪声偏移
Optimizer 优化器
Network Alpha 网络α
Learning Rate Scheduler Number Cycle 学习率数字周期
2. Experimental Setup 验证维度
Dataset: 30 images, each trained under four LoRA versions with variations in key parameters. 数据集:30张图像,每张图像在四个LoRA版本下训练,关键参数不同。
Evaluation Criteria: 评价标准:
Text/Prompt Integrity (how well text is preserved in output) 文本/提示完整性(文本在输出中的保存情况)
Overall LoRA Strength (extent of stylization and fidelity changes) 总体LoRA强度(风格化程度和保真度变化)
Artifact Frequency (presence of visual noise, distortions) 频率(存在视觉噪声、失真)
Realism vs. Cartoon Aesthetic (balance of photorealism and abstraction) 现实主义与卡通美学(摄影现实主义和抽象的平衡)
Seed Consistency (output stability across multiple various seeds *sample images below all have the same seed) 种子一致性(多个不同种子的输出稳定性 * 下面的示例图像都具有相同的种子)
3. Results 结果
3.1 Results with trained Loras 经过训练的Loras的结果
3.2 Results with no Loras (base model only) 无Loras的结果(仅基础模型)
4 Findings & Parameter Effects 结果和参数影响
4.1 Unet Learning Rate Unet学习率
Higher Unet LR values (0.0002–0.001) significantly increase stylization, often leading to texture destruction and less controlled details. Lower Unet LR values (0.00005–0.0001) keep outputs more subtle, maintaining finer details but requiring higher LoRA strength to have a noticeable impact. 较高的Unet LR值(0.0002-0.001)会显著增加风格化,通常会导致纹理破坏和较少的控制细节。较低的Unet LR值(0.00005-0.0001)使输出更加精细,保持更精细的细节,但需要更高的LoRA强度才能产生明显的影响。
4.2 Clip Skip 剪辑跳过
Higher Clip Skip values (3–4) remove the influence of text guidance almost entirely, instead prioritizing textures, color balance, and stylization. Lower values (1–2) preserve typography and finer print details, making them more effective for text-heavy generations. 较高的“剪辑跳过”值(3-4)几乎完全消除了文本指导的影响,而不是优先考虑纹理、颜色平衡和样式化。较低的值(1-2)保留排版和更精细的打印细节,使其对文本密集的生成更有效。
4.3 Network Dimension 4.3网络维度
Lower Network Dimension values (8–16) make LoRAs effective only at high strengths, requiring exaggerated weight application to be noticeable. Higher Network Dimension values (32–64) produce more aggressive LoRA effects, often necessitating lower strengths to avoid excessive influence over outputs. 较低的网络尺寸值(8-16)使LoRA仅在高强度下有效,需要夸大的重量应用才能引起注意。较高的网络维度值(32-64)会产生更积极的LoRA效应,通常需要较低的强度来避免对输出产生过度影响。
4.4 Learning Rate Schedulers 学习率调度器
“Cosine with restarts” introduces drastic jumps in effect at strength thresholds, making it useful for controlled variability. “Constant” keeps training stable but with limited flexibility in adaptation. “Cosine” tends to enhance 3D-like structures but results in unstable outputs across different seeds. “Linear” smooths out color transitions but can overly flatten contrast-heavy images. “重启余弦”在强度阈值处引入了剧烈的跳跃,使其对受控的可变性很有用。“恒定”可保持训练稳定,但适应灵活性有限。“余弦”倾向于增强3D类结构,但导致不同种子的输出不稳定。“线性”平滑了颜色过渡,但可能会过度平坦化对比度高的图像。
4.5 Min SNR Gamma 最小SNR Gamma
Higher Min SNR Gamma values (10–20) enhance contrast and sharpness but tend to flatten color depth, reducing natural shading. Lower values (5) retain softer gradients and allow for more depth in complex lighting conditions. 较高的最小信噪比伽玛值(10-20)可增强对比度和锐度,但会使颜色深度变平,从而减少自然着色。较低的值(5)保留较柔和的渐变,并允许在复杂的照明条件下获得更大的深度。
4.6 Noise Offset 噪声偏移
Higher Noise Offset values (0.3–0.5) introduce grain and chaos, mimicking VHS/Polaroid textures and adding analog-style imperfections. Lower values (0.05–0.1) preserve clarity and retain finer textures without unwanted distortions. 较高的“噪波偏移”值(0.3-0.5)会引入颗粒和混乱,模仿VHS/Polaroid纹理并添加模拟风格的瑕疵。较低的值(0.05-0.1)可保持清晰度并保留较精细的纹理,而不会出现不必要的扭曲。
4.7 Network Alpha 网络α
Higher Network Alpha values (16–32) amplify LoRA influence even at low strengths, often overpowering realism with more aggressive stylistic imprints. Lower values (4–8) require higher LoRA strengths to manifest noticeable effects but maintain a more subtle impact on realism. 较高的网络Alpha值(16-32)即使在低强度下也会放大LoRA的影响力,通常会以更具侵略性的风格印记压倒现实主义。较低的值(4-8)需要较高的LoRA强度来表现出明显的效果,但对真实感的影响更微妙。
4.8 Optimizers
AdamW8Bit provides predictable, controlled results, making it ideal for structured LoRA applications. Prodigy forces stronger stylization effects, leading to more chaotic analog textures and unpredictable outputs. AdamW8Bit提供可预测、可控的结果,是结构化LoRA应用的理想选择。Prodigy强制更强的风格化效果,导致更混乱的模拟纹理和不可预测的输出。
4.9 Learning Rate Scheduler Number Cycles 学习率循环次数
Higher LR Scheduler cycles introduce extreme variation between epochs, allowing for more diverse stylistic shifts throughout training. Lower cycle values maintain a more consistent stylization across training steps. 更高的LR训练周期在不同时期之间引入了极端的变化,允许在整个训练过程中进行更多样化的风格转换。较低的循环值在训练步骤中保持更一致的风格化。
5. Practical Applications of Parameters 参数的实际应用
5.1 Artifacts & Clarity 人工制品和清晰度
Higher Noise Offset values increase grain, texture, and chaotic variation. Min SNR Gamma improves clarity and sharpness in outputs. Higher Clip Skip values can reduce artifacts but may also lower overall clarity. 较高的“噪波偏移”值会增加颗粒、纹理和混乱变化。最小SNR Gamma可提高输出的清晰度和锐度。较高的“剪辑跳过”值可以减少瑕疵,但也可能降低整体清晰度。
5.2 Realism vs. Cartoon Spectrum Shift 现实主义vs.卡通光谱转移
Higher Clip Skip values push results toward photorealism, while lower values make images more stylized and painterly. Higher Unet LR values soften outputs with artistic distortions. Lower Noise Offset values produce cleaner images, while higher values introduce a gritty, film-like look. 较高的“剪辑跳过”值会使结果更接近照片级真实感,而较低的值会使图像更具有风格化和绘画感。较高的Unet LR值会软化带有艺术失真的输出。较低的“噪波偏移”值会产生更清晰的图像,而较高的值会产生粗糙的胶片外观。
“Cosine with restarts” LR Scheduler creates controlled unpredictability across generations. The Prodigy optimizer decreases consistency, increasing variation in outputs. Higher Unet LR values decrease seed consistency, leading to less predictable outputs. Lower Network Alpha values stabilize seed predictability by reducing LoRA dominance. “重启余弦”LR迭代法创造了跨代的可控不可预测性。Prodigy优化器降低了一致性,增加了输出的变化。更高的Unet LR值会降低种子一致性,导致更不可预测的输出。较低的网络Alpha值通过降低LoRA优势来稳定种子的可预测性。
5.4 Overfitting vs. Generalization 过度拟合与泛化
Higher Network Dimension values encourage overfitting, reducing flexibility in LoRA adaptation. Higher Unet LR values can cause over-memorization, leading to less variability. Higher Clip Skip values can improve generalization, allowing models to extract broader stylistic features rather than overfitting to specifics. 更高的网络维度值会鼓励过度拟合,降低LoRA适应的灵活性。较高的Unet LR值可能会导致记忆过度,从而导致可变性降低。较高的“剪辑跳过”值可以改善泛化,允许模型提取更广泛的风格特征,而不是过度拟合细节。
5.5 Parameter Sensitivity (How Small Changes Impact Outputs) 参数敏感度(微小变化如何影响输出)
Higher Network Alpha values result in small adjustments causing large output shifts. Higher Min SNR Gamma stabilizes changes, making variations less extreme. Higher Noise Offset values increase chaotic elements, making outputs more sensitive to small adjustments. 较高的网络Alpha值会导致小的调整,从而导致大的输出偏移。较高的Min SNR Gamma可稳定变化,使变化不那么极端。较高的“噪波偏移”值会增加混乱元素,使输出对微小调整更加敏感。
5.6 Fine Detail Retention 精细细节保留
Higher Min SNR Gamma values improve fine detail preservation. Excessively high Network Dimension values can cause loss of finer details. Lower Unet LR values help maintain sharpness and structural integrity. 较高的Min SNR Gamma值可改善精细细节保留。过高的网络尺寸值可能会导致丢失更精细的细节。较低的Unet LR值有助于保持清晰度和结构完整性。
5.7 Contrast & Tonal Shifts 对比度和色调变化
Higher Noise Offset values wash out tonal depth and flatten colors. Higher Min SNR Gamma values create stronger contrast, deepening shadows and enhancing highlights. The Prodigy optimizer produces harsher, more exaggerated contrast shifts. 较高的“噪波偏移”值会冲淡色调深度并使颜色变平。较高的最小SNR Gamma值可创建更强的对比度,加深阴影并增强高光。Prodigy优化器产生更严厉,更夸张的对比度变化。
5.8 Stylization vs. Photorealism 风格化与照相现实主义
Higher Clip Skip values push toward photorealism, while lower values lean into stylization. Higher Network Dimension values increase stylistic influence and exaggeration. Higher Unet LR values soften images, creating a more dreamlike, impressionistic aesthetic. 较高的“剪辑跳过”值会推动照片现实主义,而较低的值则倾向于风格化。较高的“网络尺寸”值会增加风格影响和夸张效果。更高的Unet LR值可以软化图像,创造出更梦幻、更印象派的美感。
6. Conclusion 结论
Fine-tuning individual values such as Clip Skip, Unet LR, and Noise Offset enables targeted control over stylization, realism, and text fidelity. Future studies will expand on testing parameters individually, multi-LoRA blending, and dataset balancing. 微调各个值(如“剪辑跳过”、“Unet LR”和“噪波偏移”)可实现对样式化、真实感和文本保真度的目标控制。未来的研究将扩展单独测试参数,多LoRA混合和数据集平衡。
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\nodes.py", line 1993, in load_custom_node
module_spec.loader.exec_module(module)
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\custom_nodes\comfyui_face_parsing\__init__.py", line 18, in <module>
download_url("https://huggingface.co/jonathandinu/face-parsing/resolve/main/config.json?download=true", face_parsing_path, "config.json")
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\site-packages\torchvision\datasets\utils.py", line 134, in download_url
url = _get_redirect_url(url, max_hops=max_redirect_hops)
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\site-packages\torchvision\datasets\utils.py", line 82, in _get_redirect_url
with urllib.request.urlopen(urllib.request.Request(url, headers=headers)) as response:
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\urllib\request.py", line 216, in urlopen
return opener.open(url, data, timeout)
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\urllib\request.py", line 519, in open
response = self._open(req, data)
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\urllib\request.py", line 536, in _open
result = self._call_chain(self.handle_open, protocol, protocol +
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\urllib\request.py", line 496, in _call_chain
result = func(*args)
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\urllib\request.py", line 1391, in https_open
return self.do_open(http.client.HTTPSConnection, req,
File "D:\ComfyUI-aki\ComfyUI-aki-v1.3\python\lib\urllib\request.py", line 1351, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。>
Cannot import D:\ComfyUI-aki\ComfyUI-aki-v1.3\custom_nodes\comfyui_face_parsing module for custom nodes: <urlopen error [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。>
FizzleDorf Custom Nodes: Loaded
FaceDetailer: Model directory already exists
FaceDetailer: Model doesnt exist
FaceDetailer: Downloading model
ef get_restorers():
models_path = os.path.join(models_dir, "facerestore_models/*")
models = glob.glob(models_path)
models = [x for x in models if (x.endswith(".pth") or x.endswith(".onnx"))]
if len(models) == 0:
fr_urls = [
"https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/GFPGANv1.3.pth",
"https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/GFPGANv1.4.pth",
"https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/codeformer-v0.1.0.pth",
"https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/GPEN-BFR-512.onnx",
"https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/GPEN-BFR-1024.onnx",
"https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/GPEN-BFR-2048.onnx",
]
for model_url in fr_urls:
model_name = os.path.basename(model_url)
model_path = os.path.join(dir_facerestore_models, model_name)
download(model_url, model_path, model_name)
models = glob.glob(models_path)
models = [x for x in models if (x.endswith(".pth") or x.endswith(".onnx"))]
return models
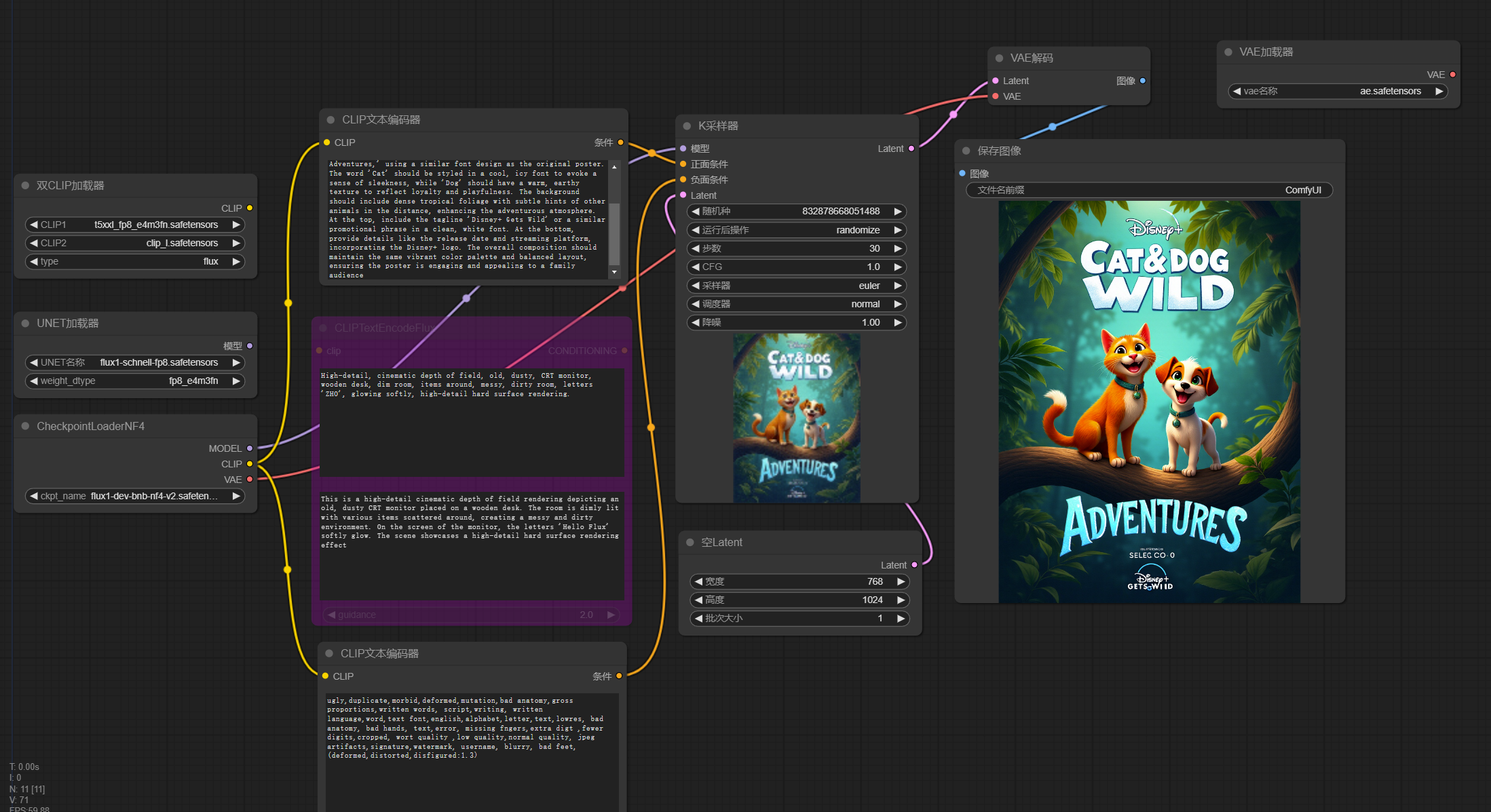
获得关键词如下:This is a digital promotional poster for the Disney+ animated film “The Ice Age Adventures of Buck Wild.” The image is a vibrant, colorful cartoon depiction set in a lush, jungle-like environment. The background features dense foliage, tall trees with broad leaves, and a variety of greenery, creating a sense of depth and immersion.
In the foreground, two anthropomorphic ground sloths, Buck and Crash, are prominently featured. They are standing on a large, gnarled tree branch, with Buck on the left and Crash on the right. Buck is holding a stick in his right hand and has a playful expression, while Crash is smiling and has his arms outstretched, as if excited. Both characters have light brown fur with darker brown stripes, and their eyes are large and expressive.
The title “The Ice Age Adventures of Buck Wild” is prominently displayed in large, bold, yellow letters in the center of the poster. Above the title, the text “Disney+ + gets wild” is written in white. Below the title, the Disney+ logo is visible, along with the phrase “Original movie from 20th Century Studios.” The poster’s overall style is bright and cheerful, with a playful, adventurous tone.
提示词如下:This image is a digital illustration, likely created in a comic book style, featuring a futuristic, cyberpunk aesthetic. The central figure is a young woman with pale blue skin and striking, large, orange eyes. Her hair is platinum blonde and styled in a sleek, high ponytail. She is dressed in a high-tech, form-fitting outfit with metallic accents, giving her a futuristic, robotic appearance. Her left hand, which is gloved in a black, mechanical-looking glove, is holding a clear glass filled with a refreshing drink, which she is sipping through a straw.
The background is predominantly black, with vibrant yellow and orange accents, creating a striking contrast that highlights the central figure. The magazine cover title, “FAVR,” is prominently displayed in large, bold letters at the top, with additional Japanese text on the left side. The word “SMOOTHIE” is written in bold, white letters at the bottom, emphasizing the theme of the cover. The overall color palette is a mix of cool blues and warm oranges, contributing to the high-tech, futuristic vibe of the artwork. The image is detailed, with a focus on the woman’s expressive face and the sleek, futuristic design of her outfit.









![[转载]Understanding Flux LoRA Training Parameters-了解Flux LoRA训练参数](https://trilightlab.com/wp-content/uploads/2025/02/flux-lora模型训练的参数对模型结果的影响表现-trilightlabs.png)