

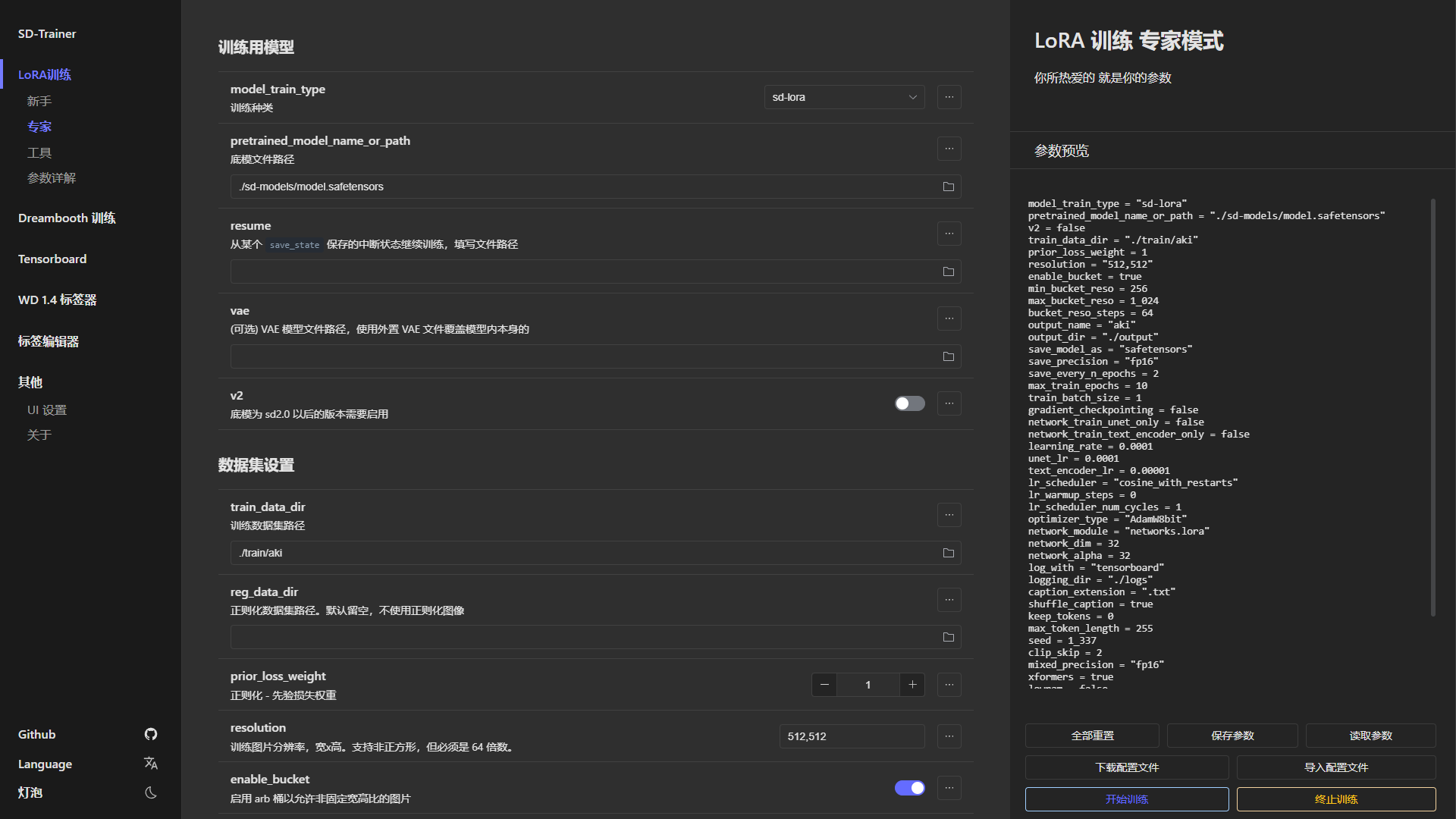
上一期文章分享了扁平插画女孩的LoRa-XL模型,训练的repeat扫描次数在10-20之间,这次我将他们的repeat提高到100-150,在同样的提示词下生成的效果如图:
masterpiece:(1.2),chahua_nvhai,,British girl,Exquisite facial details,long hair,1girl,illustration style,brown hair,wear blue dress,illustration, 5 fingers,8K,hud,Grand Budapest Hotel background,happy











头发的细节,脸部细节泛化能力都提升不少。如果你在模型训练的时候如果感觉效果没有提升,特别是XL模型训练,试试看将repeat扫描次数提高到100以上。












































































![[stable diffusion]浅谈AI游戏道具-在项目中的运用](https://trilightlab.com/wp-content/uploads/2024/01/064515616.png)





















































